
AI Security and Decision Provenance
How much is it "our" decision when AI is involved?


Based on hopes, promises, and investment numbers, AI should help us make better, faster, and cheaper decisions through different levels of assistance, augmentation, and automation. The current problem with AI is that these capabilities are built hastily on new technologies that are still experiments in progress, with limited transparency and accountability, very unclear dependencies, taking advantage of gaps in regulations, and with details of business models yet to be determined. Because AI solutions are expected to apply to any scenario in the digital space, we must assume that highly sensitive and valuable data are involved, and the outputs of these systems may have significant consequences not only for direct users. When we add AI to our decision workflows, we need to consider all factors (and actors) that can influence outcomes and carefully evaluate whether we can still call these decisions fully “ours”.
Cybersecurity is all about protecting data. That is an oversimplification, but a surprising number of security problems can be translated to protecting a specific piece of information. As we have been migrating most activities to the digital space (a process accelerated as a prerequisite for AI), we face significant challenges in managing data security. In individual contexts, the value of personal data and experiences may not be obvious, and their protection can be overwhelming with confusing UX or unclear trust boundaries between local and remote systems. In organizational contexts, challenges become even more difficult, as we deal with much more complex data flows, multiple users, and highly dynamic attack surfaces. Many of these problems are addressed by Data Governance frameworks that comprise principles, practices, and tools to manage data assets throughout their lifecycles. These methods are intended to help understand what data are stored, their sensitivity, how they are used, and the regulatory requirements that should be met. They are necessary for the effective implementation of access control, security policy enforcement, and protection of data in use, in motion, and at rest. One of the key components of Data Governance is Data Provenance, which covers the historical context of data, their origins, transformations, and authenticity. The related practice of tracking Data Lineage focuses on detailed data movements, changes, and usage across organizational systems and processes. Despite years of development, these efforts still face many practical challenges (e.g., when data of different sensitivities are imported into an analytics platform like Power BI). These challenges only become more difficult when AI is added to the systems. That said, Data Provenance and Lineage experiences might be the best starting points for addressing new critical requirements.
The trustworthiness of AI models depends on the data and human input used during their development, as well as on the transparency and accountability of that process.
AI models, like LLMs, are complex software products, usually with intricate supply chains covering software, data, and human interactions. Traditional dependencies on software artifacts can still cause frequent and significant problems. They can have a potentially very broad impact if a vulnerability exists in a common component, and they are not always accidental, as they could be backdoors intentionally introduced as part of a long-term campaign. However, AI models are not developed like traditional software - they are trained, in most cases, on top of some foundation models. The process of training a model, or adapting it to a domain or organizational context, is based on data and user input. The early stages of LLM development are critical, as flaws in training data are embedded in foundation models and can be propagated to downstream applications, a phenomenon referred to as Catastrophic Inheritance (related to data poisoning threats if intentional). In addition, the training relies heavily on human input and Value Alignment, which is originally aimed at preventing harmful outputs and behaviors by following some universal principles. However, the alignment can also be implemented based on local preferences of organizations or individuals (also a feature for personalized experiences) and shift from safeguards to shaping responses in line with a specific agenda (e.g., DeepSeek R1 and politically sensitive topics in China). The trustworthiness of AI models depends on the data and human input used during their development, as well as on the transparency and accountability of that process. Unfortunately, only a minority of foundational models have published those critical details. Open source in the AI context usually means open weights. Even less is known about the values embedded in dynamic, frequently updated frontier models hidden behind APIs.
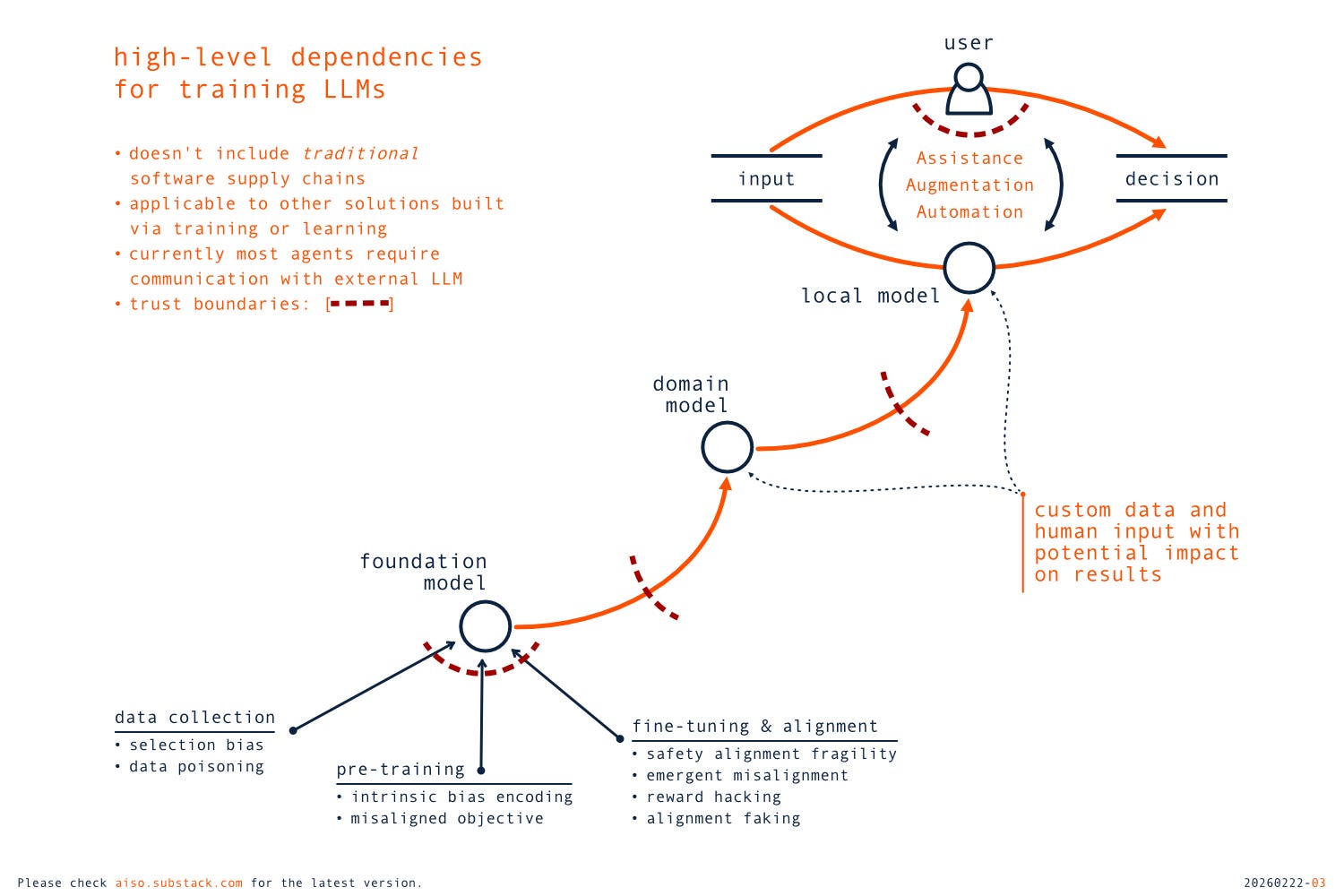
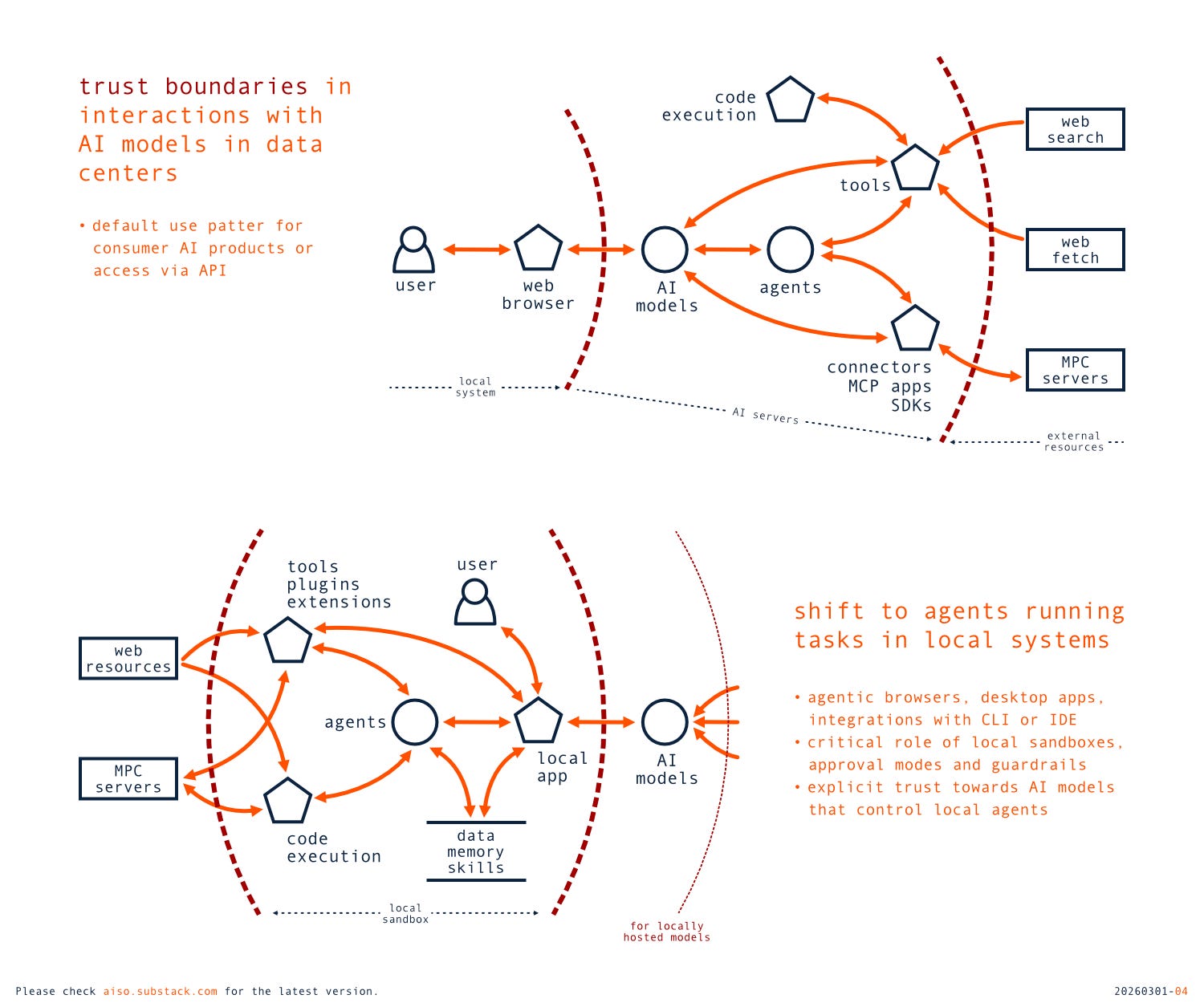
The risks of unexpected impact are not limited to the training process but also apply to the actual use of AI capabilities. The patterns for working with AI are changing; we are moving from basic conversational interfaces to AI agents specialized for specific tasks, and Agentic AI systems capable of goal decomposition, multi-step planning, distributed communication, and reasoning with memory. More and more often, that means working with complex multi-agent solutions that operate autonomously, focus on the provided goals, and across multiple trust boundaries (not always clearly defined). Interactions via a browser are still common, but we now also have agentic browsers (e.g., Perplexity Comet), desktop agentic applications (e.g., Claude Cowork), integrations with terminals (e.g., OpenAI Codex CLI), or development environments (e.g., GitHub Copilot). Details vary between configurations, but there is a clear shift towards executing actions in local systems, and the closer the integrations, the more threats need to be mitigated. That includes, for example, managing expanded attack surfaces or the now-seemingly common pattern of executing external code in local environments, which adds heavy pressure on internal trust boundaries.
More importantly, current AI agents require significant outbound communication, as most are controlled by external models (locally hosted options still have limited capabilities) and interact with 3rd party services, data sources, or other agents (human or AI). We need to be asking critical questions: how much downloaded data, results from the MCP server, or a quick answer from a human operator can be trusted in a given use context? Or do results from a specific AI pipeline meet all the requirements of a decision situation? Quality of output, inaccuracies, or hallucinations cannot be ignored, but we also need to pay close attention to potential influences from adversaries (including priorities of technology providers). These types of problems cannot be solved by providing users with source references to review or by asking them to explicitly trust a remote server. They cannot also be easily addressed by the traditional approach to input validation (unstructured data in open interactions), and mitigations aimed at preventing prompt injections are insufficient to treat external input as trusted in the decision context.
When it comes to the application of AI in real-life scenarios, we still seem to be missing a balance between benefits and risks. There is a lot of not-yet-realized optimism, systemic fear of missing out, and an urgent need to prove that benefits are right around the corner to justify the heavy expenses. When talking about risks, we often tend to wander easily into existential fears about AI, while at the same time feeling surprisingly comfortable with accepting everyday unknown risks and unmitigated threats. Experiments in delegating authority for complex decisions to AI systems are hastily moved into production, while practical regulations, frameworks, and best practices try to catch up (with significant obstacles). In the background, more and more is at stake, as to prove their values, AI solutions are implemented in non-trivial scenarios that usually also have non-trivial consequences (often unintentionally and unknowingly). It would be naïve to assume that the severity and impact of every decision are completely understood. Even in regulated industries, with well-defined decision flows and strict accountabilities, the specific patterns and practices are unlikely to meet the requirements of integration with AI agents. The long-term consequences of decisions about using AI in specific contexts are unfortunately not limited to direct users or current executives (who will often move to the next opportunity by then). That impact is potentially much broader, affecting everyone who finds themselves on the receiving end of decisions made with help from AI (often without their knowledge or consent). If we want to avoid surprises (the ultimate goal of security efforts), we need to pay very close attention to Integrity, Availability, and Confidentiality of decision processes that are automated or augmented with AI (likely in that particular order).
Decision Provenance is the history of decisions, their severity and impact, the specific data used, the roles, responsibilities, and actions of all actors involved, and the environments in which they are made.
Practical AI Security requires a similar approach to decisions as we’ve been implementing with data in organizations. We need comprehensive Decision Provenance frameworks that provide a structure for all interactions between humans and AI agents, from discreet collaboration to continuous augmentation to full automation of decisions. The general definition of Provenance from NIST provides a good starting point:
The chronology of the origin, development, ownership, location, and changes to a system or system component and associated data. It may also include the personnel and processes used to interact with or make modifications to the system, component, or associated data.
Following that definition, we can think of Decision Provenance as understanding the history of decisions, their severity and impact, the specific data used, the roles, responsibilities, and actions of all actors involved, and the environments in which they are made. Following the underlying data flows is fundamental in these efforts, and existing practices can be very useful; for example, backward and forward data lineage can be applied in evaluation at the end of the decision pipeline (backward) or for proactive warnings or blocking (forward). There are also new methods focused specifically on AI data governance, such as vector lineage for embedding provenance, or with potential applications in that space, such as AI watermarking standards for tracking AI-tainted inputs and outputs.
However, decisions are more than inputs and outputs when there are interactions among AI, users, and external systems. We need a big-picture view at the level of decision workflows, including decision contexts, their impact, and the costs of errors (or delays), to determine how they could be influenced by AI. That requires knowledge of all actors, their relationships, and reliable differentiation between the actions of human and AI agents. Agents must have a strong identity, up-to-date metrics, and profiles with reputations based on their behavior history. The roles of humans and AI agents must be precisely defined, with clear ownership and accountability for delegated tasks, and user-friendly patterns for human-(in|on|out)-the-loop. For high-impact decisions, all interactions between involved actors must be captured in immutable audit trails, continuously monitored, and analyzed to detect drift, anomalies, or other unexpected conditions. That process needs to be performed in real time, with redundant methods, unique objectives (e.g., detecting accountability gaps), and always under human oversight (likely heavily augmented by locally trained models). Please note that the primary purpose of these efforts is not only incident response (which is still absolutely critical), but also continuous learning, understanding unique threats, and updating the requirements for underlying technologies to tune the system.
Working with AI can be perceived as encouraging risk-taking without accountability (ironically, also regarding decisions about using AI).
Adding AI components to internal dataflows fundamentally changes the security requirements for computing environments. There are many assumptions about the security foundations needed for AI, such as implementing zero trust, no technical debt, or managing insider threats. In every organization, they will be heavily tested in practice, as any gaps or flaws are much less likely to remain hidden. The new technical requirements related to Agentic AI also need to be quickly added (too often as an afterthought). We need operational environments with clear policies, improved identity management, robust access control, effective guardrails, strong defense-in-depth, and real-time responses covering the full agent lifecycle, from provisioning to decommissioning. But since hopes and benefits for AI go way beyond technology, so do the risks. Security becomes even more dependent on changes in human behavior. Individuals can make dangerous shortcuts and justify them as necessary, even if they provide only illusory short-term benefits. That can be especially problematic when combined with an insufficient understanding of technical limitations and messaging like using AI is no longer optional. In 2025, the use of unsanctioned AI solutions (aka Shadow AI) moved from a theoretical problem to a measurable source of breaches, data exposure, and financial loss. There are promising technical solutions to address that practical threat, but other trends will be much harder to deal with. In certain situations, working with AI can be perceived as encouraging risk-taking without accountability (ironically, also regarding decisions about using AI). That could lead to Agency Laundering, when morally suspect decisions are attributed to the system or to Distributed Responsibility - spreading accountability across multiple actors, so no single party can be fully accountable when systems cause harm. Hiding behind algorithms is not a new phenomenon, but it can become much more harmful as the adoption of AI grows. With a lack of regulations and the immaturity of AI ecosystems, we may expect a pattern of intentionally delegating to AI the decisions that are most unpopular or risky.
The proper response to the AI Revolution is focus on the consistent Evolution of our security systems in individual and organizational contexts.
There are no silver-bullet tools, products, or services that can automagically solve AI security problems. Building a proper security structure requires research and education, practical policies (roles and rules!), effective controls, operational procedures, and intelligent incident response. That is a learning process (heavily data-driven) that also involves shaping organizational culture with awareness of technical gaps, acknowledging new threats, effectively balancing security and innovation, and following principles of data-driven transparency and accountability. The proper response to the AI revolution is focus on the consistent evolution of our security systems in individual and organizational contexts. The technical solutions will be essential but also insufficient, as humans and businesses need to adapt as well, and that requires different approaches (especially if we don’t want to lose unique values along the way). In most cases, these exercises should start by establishing strong requirements for providers of AI products, services, and data. At the end of the day, these are the primary sources of impact on the decisions made with AI. That is especially important, given that accountabilities remain highly asymmetric: under the platformisation paradigm, AI model providers systematically disclaim liability and shift risk to users. That is also a good opportunity to look at the risks of overreliance on external systems, with costs, quotas, and rules of engagement still to be finalized, and the indirect impact on organizational resilience (e.g., losing competencies leads to losing independence). Obviously, dependence on external software is nothing new. Still, we have never before tried to delegate so many complex and critical tasks to machines without a full understanding of the true scope, costs, and variables that could affect our decisions.
Security is about data flows and control. AI redefines both these elements beyond digital space. The integration of AI into our decision workflows fundamentally changes existing requirements and introduces new ones. We now have much bigger, more complex, and more vulnerable systems to protect. We need to deal with unknowns in supply chains, the weekly novelty of AI capabilities, their black box nature, and the unpredictability of the human element. The benefits of AI solutions are significantly limited if adversaries can influence their results during training or operations. Protecting the integrity of decisions must be identified as a key priority for any AI security program, and Decision Provenance, grounded in data governance and security best practices, appears to be both a necessity and an opportunity. Both the benefits and risks of AI remain significant unknowns. But as hopes and promises may end in disappointment and loss of investments, the costs of likely avoidable failures may not necessarily be capped.
Updated on March 2nd, 2026, with updated diagram and other minor edits.