
Security of AI Models
We need to protect what we don’t yet fully understand


As we introduce AI technology into practical applications, we expose them to threats that must be mitigated. Some of these threats are new and unique for AI components, and they critically determine how much we should trust the obtained results. This post is a short introduction to the security of AI Models and related requirements.
In the previous posts, we looked at a layered approach to AI application security with some consideration for their USE CONTEXT. In this post, we start looking at the AI MODEL Layer, which includes core capabilities and components responsible for the function and value of AI applications, including all relevant algorithms, data, and models. AI Models are new and still dynamically evolving, complex and partially understood, yet already used in practices, often with significant and not fully realized impact. When it comes to high-risk domains or mission-critical applications, we need to be sure that a model can be trusted for use in a specific context. We need to know that when a system is shared with users and operates in a secure environment, it will produce results aligned with expectations that will be useful and not cause harm. In practice, that means that we must understand new threats that AI Models will be exposed to and be ready to provide mitigations compatible with the USE CONTEXT.
AI software is different
AI Model in the context of this post is understood in a general way, as code (models and algorithms) combined with data to deliver some value in terms of results or actions. Even though AI doesn’t have to be based on Machine Learning, we can assume that most current solutions include some training (when the model is built or tuned) and inference (when it is used). There are different deployment modes and system lifecycles, but for now, at least, AI components are still software, even though more and more they operate on dedicated hardware.
From a security point of view, however, AI software is new and different:
Models are trained, not programmed, which means they are harder to understand or test and can be less predictable, with degrading performance or challenges related to patching.
They have different attack surfaces, with complex and not obvious trust dependencies on data, services, or software artifacts (including new ones, like pre-trained models).
Finally, the flaws can be exploited in less noticeable ways, and the success of an attack may be more subtle, like returning results favorable to specific subjects.
In addition, AI models are exposed to new threats applicable to different stages of their lifecycles and strongly dependent on their USE CONTEXT. That is natural for freshly invented technologies, as new capabilities and scenarios lead to new threats and attack techniques, which require new controls and procedures. What is challenging about the current situation with AI is the unprecedented speed of development and adoption of these technologies. We can see many new models often leading to unexpected results, but also older technologies applied in brand new scenarios with much more significant impact. Unfortunately, too often, there is no time reserved for proper security analysis, and we begin to learn about attacks and discover gaps in mitigations only when these applications get released to production. In some cases, we should be able to quickly adapt to new challenges by re-using our experiences in cybersecurity. Still, in others, the actual work on mitigations is about to start.
New technologies face new threats
AI models can contain traditional software vulnerabilities in code or design. Due to massive dependencies, complex input data, and aggressive R&D cycles, such problems may be even more likely to occur. That is not what we are talking about in this post, as here we will focus on unique challenges closely related to the role of the models as essential parts of an AI system. The threats to AI models can be purely technical, but we still should look at them in a broader context as attempts to control decisions and tasks that are automated and augmented with the help of AI. The attacks aimed at AI/ML systems are not new; different types have been discussed for years, with hundreds of proof concepts and research papers. Now they have become more practical with new tactics and techniques that can be applied during the development and training of AI models and during inference when the applications are used.
The attacks against the AI models are often referred to as adversarial-machine-learning. They can have different practical goals (again, very context-dependent), but in most cases, they are aimed at extracting value from the system, altering its behavior, or completely disrupting its operations. Even if the details and context of the threats may be new and unique, these general categories should be familiar, as they translate to fundamental security properties of Confidentiality, Integrity, and Availability. In the scope of each of these properties, though, some new elements require closer attention.
CONFIDENTIALITY is related to threats of information disclosure.
In the case of AI Models, attacks against Confidentiality can be aimed at data used during training or target the model itself. Regarding the data, adversaries may interact with the system to detect the presence of specific information in the training data (Membership Inference), which could lead to leaking sensitive data points (e.g., Protected Health Information identifiers). Attackers may also try to recover the representation of data used to train a model (Model Inversion) by providing crafted input and processing the results. AI models can be very valuable due to computational costs of training, but even more often because of the use of specific data in the process. Adversaries may interact with a system to extract details of the model (Model Extraction), replicate it and create a functionally equivalent model, or use it in the development of Evasion Attacks. Obviously, data and trained models can also be extracted directly if there is no proper access control, or these assets are not identified as critical.
INTEGRITY is related to threats of tampering.
Attacks in that scope can be aimed at modifying the behavior of an AI Model, and they can be implemented during training and while using a model (inference). During the training stage, adversaries may try to insert crafted data in the training set so that the model becomes sensitive to specific inputs (Data Poisoning). That could be used, for example, against an HR system evaluating resumes, which could rank higher applications containing particular words. Similar results could also be caused by direct model modification, including scenarios with pre-trained models tuned for local usage (Model Backdoors). In the scope of inference, the most interesting attacks are based on finding adversarial perturbations that exploit the properties of a model to alter its functioning to be aligned with the adversary’s goals (Evasion Attacks). Such attacks will likely become common, as they can often be developed by interacting with AI systems. They are also not only limited to digital space as adversarial input can also be based on physical objects.
AVAILABILITY property is related to threats of Denial of Services (DoS).
The related attacks can be aimed at disrupting the operation of AI applications, degrading the quality of results, or affecting response time. They can be implemented in training and inference stages, and specific objectives can be very dependent on USE CONTEXT, targeting reputation or trust towards institution or technology/service providers. In the training stage, the already mentioned Data Poisoning approach could reduce the performance of shared models under specific conditions and create a competitive opportunity for a private version. During an AI application deployment (inference), adversaries could implement attack techniques to slow down deep learning models optimized for fast and sensitive operations. Other attacks could be aimed at negating the benefits of hardware optimization, increasing latency and operational costs (with goals similar to network Distributed-Denial-of-Service). All such attacks can be critical for high-risk domains or mission-critical scenarios but can also be applied against broadly deployed systems, e.g., clothes designed to confuse face recognition.
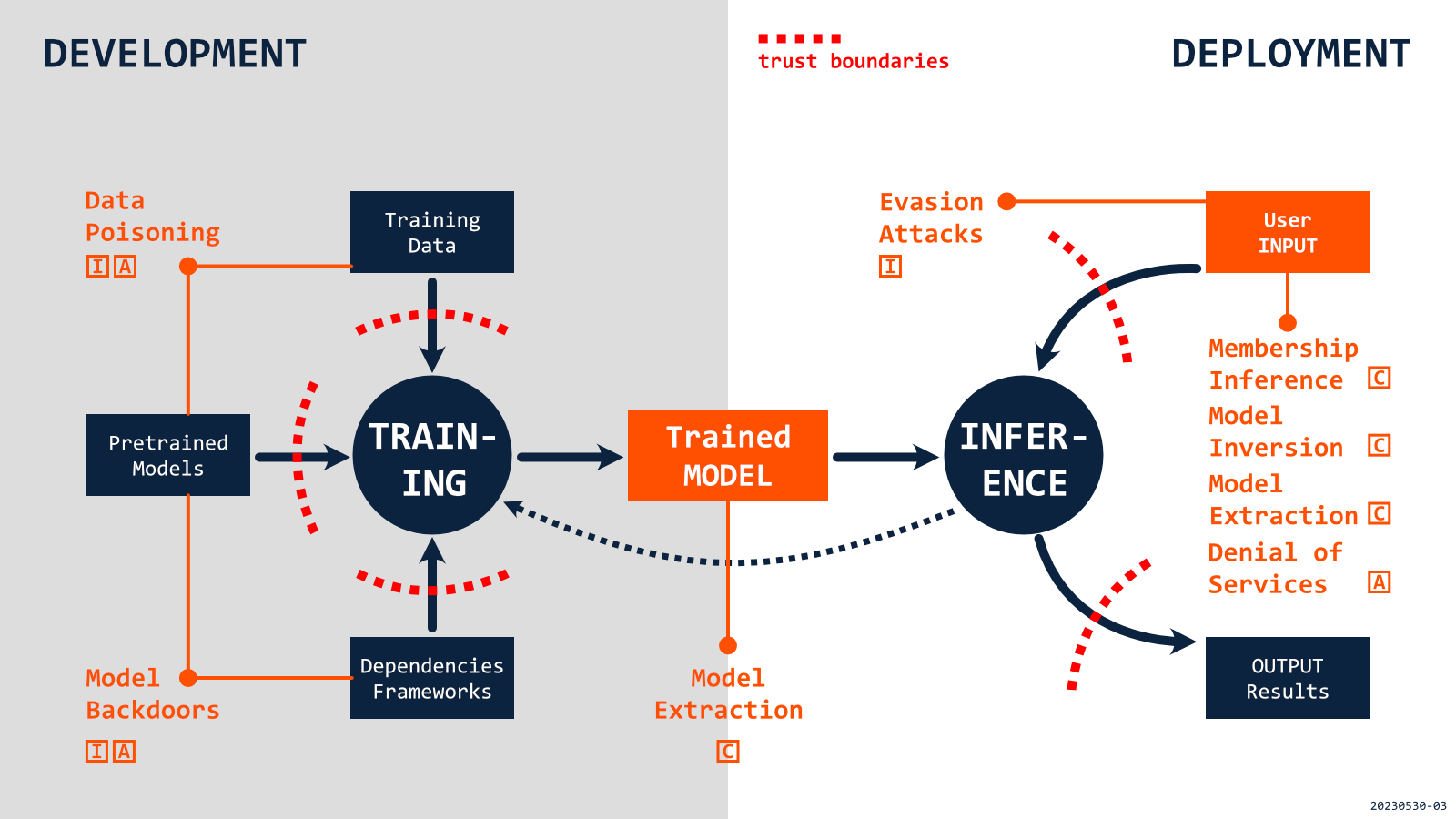
Other types of threats may have goals not directly aligned only with the core security properties (e.g., complex decision processes in healthcare). In future posts, we’ll look at more specific cases related to Authenticity, Non-reputability, and other elements of STRIDE.
Landscape is changing quickly
The main challenge for the security of AI models is the unprecedented speed of deploying these technologies to production, even if not all concerns are addressed or fully understood. That applies to models’ capabilities and characteristics, but also the impact of their practical applications with Large Language Models (LLM) as the recent examples. AI models become central elements of real-life decision workflows; as such, they start to be attractive targets of attacks. In the case of conversational systems, Evasion Attacks emerged very quickly in the form of Jailbreaking techniques, enabling crafted input to change the expected behavior of a language model and ignore its previous directives. As applications evolve, we should expect these types of attacks to become more sophisticated, for example, with Prompt Injection that can enable adversaries to exploit LLM-integrated applications without a direct interface. New ideas and techniques for making AI models more robust and resilient, like Constitutional AI, will be quickly evaluated in practice.
The development of security controls and procedures is much slower, and there are still fundamental questions regarding protecting models from users and users from models. These questions are already very relevant in the enterprise context, as there are urgent needs for effective policies regulating the local use of these technologies. Those needs will become even more pressing with more complex scenarios and types of engagements, going beyond individual users interacting with a prediction model or an assistant. We will see configuration involving multiple human parties and AI agents (e.g., negotiation processes), distributed decisions (e.g., automated hiring), downstream effects (e.g., augmented diagnostics), and multiple dependencies that must be identified and evaluated. That is why we must look at AI Models as critical components of non-trivial AI applications and related decision processes. The growing capabilities of an AI Model can lead to new benefits and opportunities but also to new threats and requirements that must be addressed. As mentioned earlier, an AI model can be suitable for one USE CONTEXT, may have additional requirements for another, and be entirely unacceptable for a third one. With dynamically changing models and contexts, many moving pieces are on the board.
The theoretical threats against AI models can quickly become real problems when we put technology into use without proper attention and diligence. Protecting a model's Integrity, Availability, and Confidentiality is the crucial task of AI security. We need to assume that our understanding of AI models and related security requirements is limited and we have gaps in controls and procedures. That assumption cannot become an excuse from due diligence but rather a reminder that we need to be aware of the limitations and constraints of technologies to make informed decisions about accepting risks for their applications. AI models play a critical role in the security of AI systems, and proper analysis of how they can be attacked is unavoidable. That investment can be beneficial for the overall quality of an AI system, as by building solutions that are robust to adversarial input, we should also make them more robust to random failures. In that way, addressing security needs can be a driving force for stronger foundations of trustworthy AI.
The visualization in this post is inspired by different diagrams of AI systems, including some from MITRE or Hackernoon. This is still a work in progress, so please expect it to be updated.
It's great that you are using STRIDE in the AI world. I think this is going to have greater importance than we currently use.